Hugging Face Introduces 'Training Cluster As A Service'
Hugging Face has officially introduced their upcoming LLM training tool called ‘Training Cluster as a service’ to simplify the creation and training of generative AI models.
Andy Hoo
Updated September 5, 2023

Photo by Gabriel Vasiliu on Unsplash
Reading Time: 2 minutes
Hugging Face has recently introduced their upcoming ‘Training Cluster as a service’ which will enable users to train their large language models (LLMs) at scale on their infrastructure.
In a recent tweet, Julien Chaumond, Co-Founder of Hugging Face, has recently revealed the upcoming service that will open accessibility to a large compute cluster for large-scale model training.
As stated, customers can simply push a single-node LLM training code and the tool will scale their training cluster-wide, using their open source tools. Consequently, customers will have access to the output inclusive of logs and final checkpoints.
According to Hugging Face, users can:
- Train their own foundation model - a model that is optimized for a user’s specific domain and business needs.
- Keep control of their data - users have access to the whole training output, checkpoints, and logs.
- Access Infra Expert support - from people with experience on large-scale training.
Reportedly, Hugging Face introduced a service-oriented approach to AI model training by integrating NVIDIA’s DGX Cloud infrastructure into their platform.
Moreover, NVIDIA teamed up with Hugging Face in efforts to supercharge LLM training and customization within the Hugging Face platform.
“We run the training for you and scale it to thousands of GPUs,” Hugging Face said in a release.
Furthermore, users can try some high-level parameters on the landing page and get an estimate of time and money required.
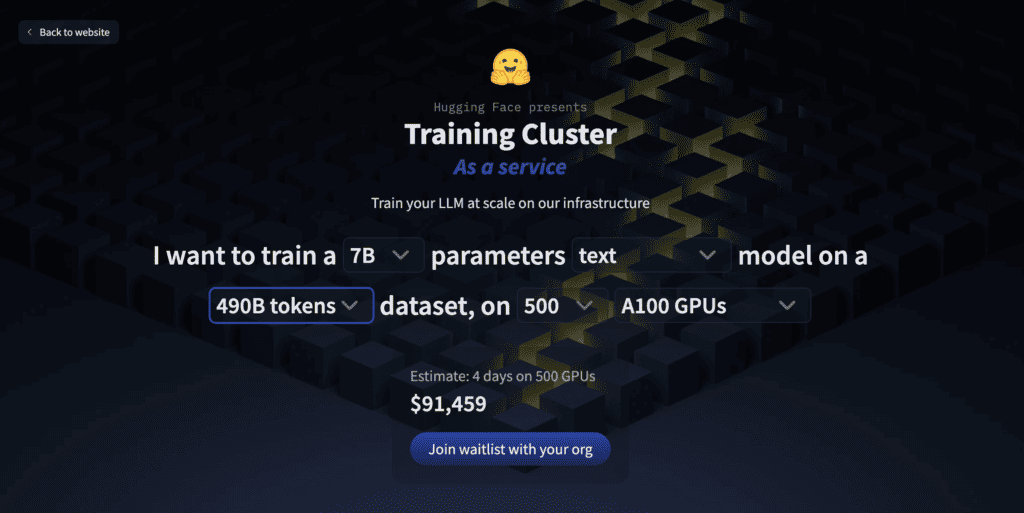
Now, users can gain access to this new service by joining the waitlist.
In previous reports, Hugging Face has recently launched a visual language model that has the ability to process images and text inputs, and turn them into coherent text outputs.
Definitely, Hugging Face continues to make cutting-edge tools that allows users to easily train their models and streamline the whole process of training and fine-tuning LLMs.
Want to Learn Even More?
If you enjoyed this article, subscribe to our free newsletter where we share tips & tricks on how to use tech & AI to grow and optimize your business, career, and life.


